광주인력개발원 일일포스팅(메모장)
15주차 목 1130(데이터베이스_수집_가공_2)
Jumbo96
2023. 12. 4. 09:15
728x90
반응형
### 사용할 데이터 읽어들이기
# 데이터프레임 변수명 : df_bus_card_tot
df_bus_card_tot = pd.read_csv("./01_data/all/df_bus_card_tot.csv")
print("갯수 : ", len(df_bus_card_tot))
df_bus_card_tot.head(1)
승차시각 하차시각 승객연령 환승여부 추가운임여부 승차정류장 하차정류장 버스내체류시간(분) 기준년도 기준월 기준일 기준시간 기준시간(분)
0 2020-01-02 05:10:49 2020-01-02 05:18:44 일반 N N 양덕차고지 동부초등학교 7.92 2020 1 2 5 10### 시각화 라이브러리
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
### 그래프 내에 한글이 포함된 경우 폰트 처리가 필요함
# - 한글 깨짐 방지
### 폰트 환경설정 라이브러리
from matplotlib import font_manager, rc
plt.rc("font", family = "malgun Gothic")
### 그래프 내에 마이너스(-) 표시 기호 적용하기
plt.rcParams["axes.unicode_minus"] = False
승차시각 하차시각 승객연령 환승여부 추가운임여부 승차정류장 하차정류장 버스내체류시간(분) 기준년도 기준월 기준일 기준시간 기준시간(분)
0 2020-01-02 05:10:49 2020-01-02 05:18:44 일반 N N 양덕차고지 동부초등학교 7.92 2020 1 2 5 10기준월 및 기준일자별 버스 이용량 시각화 분석
### 사용할 컬럼 : 기준월, 기준일, 승객연령
# - 사용할 집계함수 : count
# - 이용량 집계를 위한 함수 : prvot_table() -> 히트맵 사걱화시 데이터 생성
# - 사용할 그래프 : 히트맵(hitmap)
### 데이터 count 집계하기
# - y축 : index
# - x축 : columns
# - 집계 : count(승객연령)
df_pivot = df_bus_card_tot.pivot_table(index = "기준월",
columns = "기준일",
values = "승객연령",
aggfunc = "count")
df_pivot
기준일 1 2 3 4 5 6 7 8 9 10 ... 22 23 24 25 26 27 28 29 30 31
기준월
1 9365.0 16164.0 16590.0 12530.0 9515.0 15474.0 12981.0 15785.0 16760.0 17495.0 ... 17229.0 17399.0 9112.0 5923.0 7770.0 5468.0 14464.0 16034.0 15868.0 16186.0
2 11801.0 8523.0 15830.0 15488.0 14902.0 14376.0 15700.0 11358.0 8316.0 15582.0 ... 5654.0 2898.0 5932.0 4469.0 5344.0 5417.0 5488.0 3757.0 NaN NaN
3 2399.0 6538.0 5691.0 5976.0 5828.0 6150.0 4111.0 2826.0 6879.0 5336.0 ... NaN NaN NaN 131.0 2889.0 4976.0 3868.0 1241.0 5143.0 2487.0
결측치(NaN) 처리하기
### 모든 결측치(NaN)는 0으로 대체하기
df_pivot.fillna(0)
df_pivot
기준일 1 2 3 4 5 6 7 8 9 10 ... 22 23 24 25 26 27 28 29 30 31
기준월
1 9365.0 16164.0 16590.0 12530.0 9515.0 15474.0 12981.0 15785.0 16760.0 17495.0 ... 17229.0 17399.0 9112.0 5923.0 7770.0 5468.0 14464.0 16034.0 15868.0 16186.0
2 11801.0 8523.0 15830.0 15488.0 14902.0 14376.0 15700.0 11358.0 8316.0 15582.0 ... 5654.0 2898.0 5932.0 4469.0 5344.0 5417.0 5488.0 3757.0 NaN NaN
3 2399.0 6538.0 5691.0 5976.0 5828.0 6150.0 4111.0 2826.0 6879.0 5336.0 ... NaN NaN NaN 131.0 2889.0 4976.0 3868.0 1241.0 5143.0 2487.0
히트맵(gitmap) 시각화
### 그래프 전체 너비, 높이 설정
plt.figure(figsize=(20, 10))
### 그래프 제목 넣기
plt.title("기준월 및 기준일자별 버스 이용량 분석")
### 히트맵 그리기 : 히트맵은 seaborn 라이브러리에 있습니다.
# - annot : False는 집계값 굼시기, True는 집계값 보이기
# - fmt : ".0f"는 소숫점 0자리까지 보이기 (분석에서는 보통 3자리 씀 .3f)
# - cmap : 컬러 색상그룹
sns.heatmap(df_pivot, annot=True, fmt=".0f", cmap="rocket_r")
### 그래프 표현
plt.show()
"""
(해석)
- 1월~3월까지의 이용량을 분석한 결과 1월에 가장많은 이용량을 나타내고 있으며,
2월에서 3월로 가면서 이용량이 점진적 줄어들고 있는것으로 확인됨
- 줄어드는 이유는 포항시의 특성상 외부에서 관광객의 유입에 따라,
버스를 이용하는 사람들이 많을 것으로 예상됨
- 이에 따라, 포항시 관광객에 대한 데이터를 수집하여 해당 년월에 대한 데이터를
비교 분석해볼 필요성이 있음
"""
기준일 및 기준시간별 버스 이용량 시각화 분석
### 데이터 count 집계하기
# - y축 : index
# - x축 : columns
# - 집계 : count(승객연령)
df_pivot = df_bus_card_tot.pivot_table(index = "기준일",
columns = "기준시간",
values = "승객연령",
aggfunc = "count")
df_pivot
### 결측치 처리하기
df_pivot.fillna(0)
plt.figure(figsize=(20, 10))
plt.title("기준일 및 기준시간별 버스 이용량 분석")
sns.heatmap(df_pivot, annot=True, fmt=".0f", cmap="rocket_r")
plt.show()
"""
(해석)
- 버스 이용량에 대한 분석결과,
- 일반적으로 출/퇴근 시간에 많아야할 버스이용량이, 포항시의 경우
오후 시간대에 이용량이 밀집되어 있음
- 특히, 오후 1시, 3시에 높은 이용량을 나타내고 있음
- 이는 출/퇴근 시간에 자가 차량을 이용한느 사람이 많을 수도 있다는 예상이 을 할 수 있으며,
인구 분포가 노령인구가 많기에 오후에 잉ㅇ자가 많은 수도 있을 수 있음
- 따라서, 포항시 인구현황 데이터, 경제활동인구 분석을 통해 비교 분석이 가능할 것으로 예상됨
- 또한, 해당 이용량이 높은 시간대에 노선을 확인하여 특성 확인도 필요할 것으로 예상됨
"""
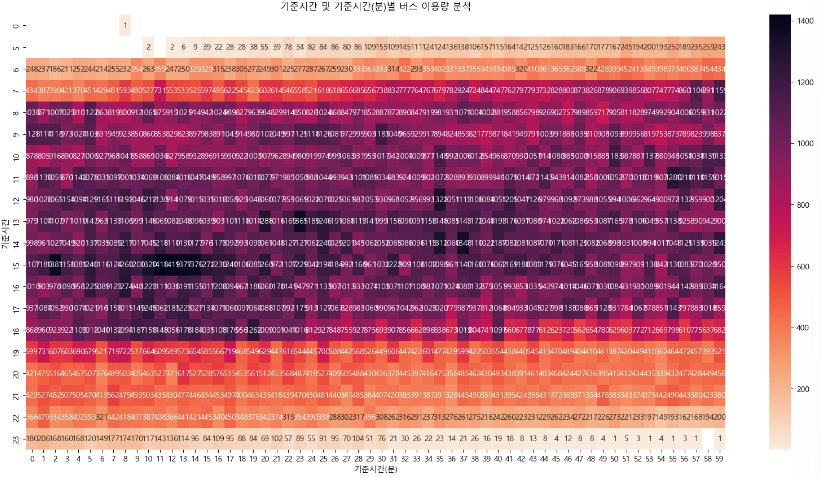
기준시간 및 분별 버스 이용량 시각화 분석
### 데이터 count 집계하기
# - y축 : index
# - x축 : columns
# - 집계 : count(승객연령)
df_pivot = df_bus_card_tot.pivot_table(index = "기준시간",
columns = "기준시간(분)",
values = "승객연령",
aggfunc = "count")
df_pivot
### 결측치 처리하기
df_pivot.fillna(0)
plt.figure(figsize=(20, 10))
plt.title("기준시간 및 기준시간(분)별 버스 이용량 분석")
sns.heatmap(df_pivot, annot=True, fmt=".0f", cmap="rocket_r")
plt.show()
"""
(해석)
- 출/퇴근 시간대의 버스이용량을 볼 때 오전 7시 55분 ~ 8시 10분 사이에 이용량이 많은 것으로 보이며,
- 퇴근 시간대의 경우에는 오후 6시 ~ 6시 20분까지 이용량이 많은 것으로 보인다.
- 특히 오후 3시 20분까지 버스 이용량이 매우 크게 나타나고 있음
- 오후 시간대 이용자에 대한 추가 확인은 필요할 것으로 보임
"""
### 데이터 count 집계하기
# - y축 : index
# - x축 : columns
# - 집계 : count(승객연령)
df_pivot = df_bus_card_tot.pivot_table(index = "기준일",
columns = "기준시간",
values = "버스내체류시간(분)",
aggfunc = "mean")
df_pivot
### 결측치 처리하기
df_pivot.fillna(0)
plt.figure(figsize=(20, 10))
plt.title("가준일 및 시간별 버스내체류시간(분) 시각화 분석")
sns.heatmap(df_pivot, annot=True, fmt=".3f", cmap="rocket_r")
plt.show()
"""
(해석)
- 매월 1일 많은 사람들이 장거리버스를 이용며 05시에 유독이용량이 많은 이례적인 데이터를 보이며,
- 출근시간보다 퇴근시간에 버스이용량이 많은것을 볼 수 있다. 이를 바탕으로
- 다른 데이터를 추가적으로 봐야겠지만 회사의 출근버스나 다른 대중교통 이용 후 퇴근은 퇴근시간대의 대중교통(버스)로 할 경우도 예상됨
- 포항시의 주변 상권(경제활동인구)의 출/퇴근 시간의 영향을 받을 수도 있을 것으로 예상됨
- 7시 이후로는 장거리 이용자는 보편적으로 나타나고 있으며,
위에서 분석한 기준일 및 시간별 이용량 분석에서 확인한 바와 같이 7시 이후의 버스 이용량도 급격하게 줄어드는 것으로 보아,
저녁 시간 버스 이용이 현저이 낮은 것으로 여겨짐
- 장거리 이용자가 많은 시간대에 급행버스의 도입에 대한 추가 확인은 필요할 것으로 여겨짐
"""
시간대 및 승객연령별 버스내체류시간(분) 시각화(막대그래프)
### 필요한 데이터 : 기준시간, 승객연령, 버스내체류시간(분)
df_temp = pd.DataFrame()
df_temp["기준시간"] = df_bus_card_tot["기준시간"]
df_temp["승객구분"] = df_bus_card_tot["승객연령"]
df_temp["버스내체류시간"] = df_bus_card_tot["버스내체류시간(분)"]
df_temp
기준시간 승객구분 버스내체류시간
0 5 일반 7.92
1 5 일반 32.18
2 5 일반 3.68
3 5 일반 34.48
4 5 일반 4.48
... ... ... ...
842603 23 일반 5.07
842604 23 일반 4.05
842605 23 일반 7.67
842606 23 일반 11.35
842607 23 일반 7.42그래프 시각화 하기
fig = plt.figure(figsize=(25,10))
plt.title("시간 및 승객구분별 버스내 체류시간(분단위) 분석")
### hue : x축 및 y축을 기준으로 비교할 대상 컬럼 지정(번주형 데이터를 보통 사용)
sns.barplot(x="기준시간", y="버스내체류시간", hue="승객구분", data=df_temp2)
plt.show()
### histplot 시각화 : 두개 그래프 조합 (밀도 그래프라고 칭하기도 합니다.)
plt.figure(figsize=(12,4))
plt.title("시간 및 승객구분별 버스내 체류시간(분단위) 분석")
sns.histplot(data = df_temp2,
x = "기준시간",
### 사용할 막대의 최대 갯수
bins = 30,
### 막대그래프 밀도 선그리기
kde = True,
### 범주 데이터
hue = "승객구분",
### 여러 범주를 하나의 막대에 표현하기
multiple = "stack",
### 비율로 표시
stat = "density",
### 막대 너비 : 0.6은 원본 100% 사이즈에서 60% 축소한 너비사이즈
shrink = 0.6)
plt.show()
승하차정류장별 버스내체류시간(분) 상위 30건 시각화 분석
df_bus_card_tot
### 구간(승차정류장 ~ 하차정류장)별 버스내체류시간(분) sum() (그룹화)하기
### - 내림차순 정렬
### - 상위 30개 추출
# df_temp3 = pd.DataFrame()
# df_temp3["승차정류장"] = df_bus_card_tot["승차정류장"]
# df_temp3["하차정류장"] = df_bus_card_tot["하차정류장"]
# df_temp3["버스내체류시간(분)"] = df_bus_card_tot["버스내체류시간(분)"]
# df_temp3
df_temp3 = pd.DataFrame()
df_temp3["승하차정류장"] = df_bus_card_tot["승차정류장"] + "-->"+ \
df_bus_card_tot["하차정류장"]
df_temp3["버스내체류시간"] = df_bus_card_tot["버스내체류시간(분)"]
df_temp3
# ### 그룹화 하기
# df_temp3 = df_temp.groupby(["승차정류장", "하차정류장"], as_index=False).sum()
# df_temp3 = df_temp3.sort_values(by=["버스내체류시간(분)"], ascending=False)
# df_temp3.head(30)
### 승하차정류장별 체류시간 그룹화하기
df_temp_gp = df_temp3.groupby(["승하차정류장"], as_index=False).sum()
df_temp_gp = df_temp_gp.sort_values(by=["버스내체류시간"], ascending=False)
### 상위 30건 추출하기
df_temp_30 = df_temp_gp.head(30)
df_temp_30
선그래프 시각화 하기
plt.figure(figsize=(12,4))
plt.title("승하차정류장별 버스내 체류시간 분석")
### 선그래프
plt.plot(df_temp_30["승하차정류장"], df_temp_30["버스내체류시간"])
### x축 및 y축 제목넣기
plt.xlabel("승하차정류장")
plt.ylabel("버스내체류시간(분)")
### x축의 값의 기울기를 이용하여 조정하기
# - xticks() : x축을 컨트롤하는 함수
plt.xticks(rotation=290)
### 격자선 표시하기
plt.grid(True)
plt.show()
"""
(해석)
- 시외버스터미널 --> 죽도시장으로 가는 노선에서 승하차가 많은 것으로 보인다.
노선 중이 많은지 종점에서 많이 내리는지 확인이 필요하다.
- 죽도시장을 종점으로 둔 버스가 많은 것으로 보이지만 종점에서 출발하는 버스는 데이터 확인이 필요하다.
-
"""728x90
반응형